Bridging the gap
At the recent Data Modelling Zone (DMZ) in Germany I presented an overview of the ideas around Data Warehouse Virtualisation and the thought processes leading up to this. In this post I wanted to elaborate on some of these ideas a bit further, as together they can be combined to allow something even more powerful. This post provides an overview of how various (technical) concepts together can help faster delivery of meaningful information to the people that need it.
One of my key takeaways from DMZ was that, for the first time really, I strongly feel that that a bridge can be created between true top-down information modelling and bottom-up (generation of) data integration. You can see that structured conceptual (for instance Fact Based / Oriented) modelling approaches can all but ‘touch’ the world of complex data integration at the technical level – free from packaged software solutions. The various case tools for modelling can capture information metadata and distil this to source-to-target mappings or graphs, while ETL generation techniques can capture this and generate physical structures for both the model and data integration.
This makes it even more relevant to explain how various proven concepts together create an incredibly solid foundation for Data Warehousing and Virtualisation. My view is that we, by connecting proper information modelling to these concepts, can (finally) step away from the discussions around physical model and ETL implementation and move towards more value-added work.
I find this fascinating, because we have used these exact terms before when talking about ETL generation in the early days. Remember that? We could move from manual ETL development towards spending more time on value-added work; the data modelling and pattern design. I think that we have everything in place now to take a step further and leave the world of automation and physical design behind us as well.
I will explain what I mean by this below, but a good recent example is the conversation about Hash Keys versus Natural Business Keys. With the concepts in place as I’ve outlined in the rest of this post, we don’t really need to talk about these kinds of technical decisions anymore. We are at a stage where the best fit for physical implementation can be generated from metadata as well.
By continuing to build on the foundations provided by ETL generation and virtualisation we are working towards further abstraction of Data Integration development to the level that we can develop ‘sensors’ – environmental parameters – that understand what kind of physical implementation makes the most sense. The generation / virtualisation becomes an ‘engine’ that can behave differently, and even on the fly (thanks to DWH Virtualisation!), using input from these sensors and (re)generate database structures and ETL processes accordingly.
Easy examples of this kind of thinking are automatically detecting fast-changing attributes to trigger a Satellite split in Data Vault, or changing from a Hash Key to a Natural Business Key depending on the composition of the business key values and technical infrastructure. We don’t need to ‘model’ for a hash key or not, but can let the systems decide this.
The bottom-up approach explained
Although I have a long history working with information modelling techniques (i.e. NIAM and FCO-IM), my approach has usually been bottom-up as I am usually drawn to technology. Consider the following picture below, which uses the Lego analogy to explain how different concepts and thought processes have been stacked up throughout the years to enable increasingly robust and flexible solutions and concepts.
As we will see, we need to consider and support them all a they all have a role to play. We will review these from a ‘bottom-up’ point of view.
![]()
Stage 1 – Manual ETL development – understanding the patterns
As many of you, I have been started out by manually developing ETLs to load data into a defined, custom target model based on a variety of ‘source-to-target mappings’. This typically involves lots of customisation due to the specific transformations required to map data to the designated target state. Because of this high degree of customisation there are only limited ways to automate development, and in the early days there was not a lot of native support for this in ETL software either.
Lack of resources is often a fertile breeding ground for innovation, and various hybrid techniques where defined that allowed for more genericity in ETL patterns. I have been involved with a couple, but when Data Vault came along I realised this was more mature and switched to this new technique around 2005. What manual ETL development has provided are the understanding of the ETL patterns, and the realisation that automation is direly needed to make Data Warehousing a success. To ‘do Data Warehousing right’ you need ETL generation.
Stage 2 – ETL Generation – improving speed to value
‘Doing Data Warehousing right’ in this context means many things, but one of them is that pattern-based approaches support the idea of generating (seemingly) redundant ETL processes to support greater degrees of parallelism. For example, the idea that you can load various Satellites (connected to the same Hub) each from a different source in different order. This would require the Hub ETL to be created many times, which is something not easily done manually. As a result he luxury of supporting parallelism is often sacrificed under project pressure.
I cannot repeat often enough how valuable it is to stay flexible when it comes to ETL generation, and to always make sure you can re-generate everything at all times. Patterns change, and so do modelling approaches. If you keep investing in ETL generation you will always be able to evolve your data solutions with these new ideas and improvements. ETL generation of course simply increases the time to value as you are able to deliver output faster (and more consistently), but also helps in reducing technical debt when tweaks to the patterns are applied.
Stage 3 – Persistent Staging – providing flexibility
At some point I introduced the idea of introducing a ‘Persistent Staging Area’ (PSA), something I’ve been writing a lot about. This idea came to mind when I realised that we could start collecting data immediately if we create an archive to store raw transactions at the onset of the project. This means we can take a bit more time to figure out what it all means (i.e. do the modelling) without losing ‘history’. We start ‘recording’ information from day 1. This is relevant, because not all systems store previous versions of information (properly, or at all).
A PSA really is a copy of the Staging Area with an effective date – the Load Date/Time Stamp, or LDTS. The LDTS definition is borrowed (and adapted) from Data Vault, and is consistently the date/time that is captured when the information first hits the DWH environment (usually the Staging Area). This is absolutely critical to support deterministic processes, and is the cornerstone for replaying transactions.
A Staging Area table is transient (truncate / load) in nature and a PSA is, well, persistent. ETL generation is required to support a PSA because of the volume of tables, but the PSA template is also one of the most straightforward and easy to automate.
If you imagine you start capturing transactions early and complete your Data Warehouse design / model some time later, you can imagine you need to find a way to ‘replay’ these transactions to load into the Data Warehouse. This requires the DWH patterns such as Hubs, Links and Satellites need to be able to do this, which is a complication of the pattern (but very worth it). Hubs and Links natively support this due to their definition, but time-variant tables such as Satellites require special attention. For an idea please read this post.
The PSA has many (more) benefits, but in this context it has contributed the support the ability to load multiple changes in one go – in my mind a key ETL requirement. After all, when you finally have your data models completed you don’t want to just get the latest version of the information. The PSA drives the ability to load and refactor in a deterministic way.
Stage 4 – Re-initialisation – making things deterministic
To enable the replaying of transactions from the PSA I developed what I refer to as the ‘re-initialisation’ concept. You basically truncate parts of your model, repopulate your Staging Area from the PSA archive using a script and reload everything using the standard DWH patterns.
Re-inialisation simplifies the process of fixing issues, since you can rely on the information to be back in place the next time you run – exactly the same as it was before it was truncated. I use this a lot in projects as it is a very easy way to make changes.
Now why would you do that? For one this means you now have a way to split out the use cases of information, while keeping a door open to change your mind. For instance, Data Scientists can work on data while findings and definitions are incorporated into a more structured format such as a DWH model.
You can start to refactor the design whenever it makes sense to do so – and you probably need to. Why?
Stage 5 – Refactoring – accepting that models will change
Well, basically because we get it wrong. We find flaws in our approach, our patterns and let’s face it – our models as well. To me that’s just human nature.
There is a strongly rooted idea that a DWH model needs massive upfront thinking to get it 100% right from the start. Indeed, many DWH architectures are relying on this to be true since no fall-back mechanisms (such as a PSA) are in place. Hybrid modelling techniques such as Data Vault, Anchor etc. have been pitched to allow flexibility to counter this which is true, but only partly so.
Even using Data Vault I frequently find that fundamental decisions need to be redone, for instance wrong business keys were used or wrong relationships were created. Or simply progressive thinking makes you change your views on how to model transactions (i.e. as Links or Hubs?). In some cases this can arguably be refactored using available information in the Data Vault, but this is complex and cumbersome. In other cases however it is simply not possible to refactor because of breaking errors (destructive transformations). Either way, it is always easier to be able to drop the structures, tweak the metadata and generate everything (structures and ETLs) in a different way.
Another way of looking at this is that in the traditional Data Vault pitch there is the notion of the ‘single version of the facts’, and pushing business logic upstream so you can iteratively explore and define requirements. This is all about defining the Data Marts, or Information Marts and supports the process of getting clarity on business requirements because ‘the business doesn’t know what it wants’.
Surely we make mistakes in the underlying DWH layer as well? Don’t you look back at some models and think that in hindsight another solution would have been more viable?
This is one of the single most controversial ideas. It basically means that the DWH layer itself is no longer the core model, but really a sort of schema-on-read on underlying raw data. You can still persist things of course, but the tools that are now in place allow you to change your mind and evolve your thinking with the organisation.
This is a critical mindset for information modellers: we will make mistakes and are better off designing for change than to try to achieve a one-off perfect model. The fact is that in every business there is different (usually very limited) understanding of what data means, and it ‘is a process’ to get clarity and understanding how information should be accurately represented in data models. See this link for more information on this.
The same applies for ETL patterns. I have been working with Data Vault & automation techniques for more than 15 years now and I still find the occasional bug or progressive thinking that makes me want to reload the environment in a slightly modified version. Adopting a mindset for refactoring (‘design for change’) supported by a PSA and (deterministic) re-inialisation allows for this.
Stage 6 – Virtualisation – abstracting data integration away
We have arrived at the point that we can:
- Drop and re-create not only the Data / Information Marts, but also the entire DWH layer and rebuild everything deterministically (from metadata)
- Regenerate all ETL processes to populate the DWH objects (using a PSA and re-initialisation)
If we can do this we can now ‘virtualise’ the Data Warehouse layer completely. What we essentially have is a series of views that mimic the ETL processes and tables, with the ability to either generate ETLs to physical tables – or a virtual representation of this. This is achieving maximum flexibility (sometimes at the cost of performance) and allows you to leverage different technologies to get the results to end-users extremely fast and at a great value-for-money. DWH virtualisation greatly increases the ROI.
In the best implementations, DWH virtualisation allows you to work at the level of simple metadata mappings and the ‘technical stuff’ all will be generated. This is the stepping stone for working with graph models later on as this is an easier way to manage metadata.
Stage 7 – Platform agnosticism – enable scaling-out
Before we do this, and to make these concepts truly work, we need to be able to extend this to other technologies. At this stage I have a library of code that supports the above concepts (to varying extents depending on where my project focus is) consisting of:
- SSIS using Biml
- SQL / T-SQL / PL-SQL stored procedures
- SQL Views
- Pentaho
- Data Stage
- Informatica Powercenter
This is hard to keep up with, and my answer is in API style collaboration. I am setting up various Githubs and collaboration ventures to be able to keep everything up to date and meaningful, both for myself and for whoever is interested. Have a look at the collaboration page for more information.
What this really means is that we define the rules how the concepts should work (be implemented) on other platforms, which is mainly a technical consideration. For our engine, platform agnosticism delivers both the parameters we need to make the physical design decisions but also of course the ability to easily move between technical infrastructures.
As an example (and these are real implementations), you can store the PSA as files (i.e. HDFS or S3) and use MPP techniques (Redshift, Azure, Hadoop) to generate the DWH layers from metadata, generate the loading processes, generate the marts, populate the consuming (BI) areas and then power down all the nodes. Scale up and out when you need to.
This is all very powerful stuff, moving from a traditional SQL Server style an Azure Data Lake, scale-out to Oracle or move to S3 and Redshift becomes possible at the click of a button and can be managed metadata-driven.
Stage 8 – Graph modelling – abstracting the designs
All that is required now is the ability to easily manage this, which is by now all but a few metadata tables. Please have a look at the metadata model collaboration for more information, this is freely accessible and open to changes. In my opinion ETL /DWH metadata lends itself very well to graph models and with the rules and framework that are now in place the graph becomes a great central point of ‘doing everything’.
There are various options to achieve this, for instance:
- Directed Graph Markup Language (DGML) which is standard in Visual Studio and uses XML to capture edges and nodes. This is great for representation, but has very limited interactivity.
- D3, which is a JavaScript visualisation library / framework that supports interacting with objects
- Commercial libraries such as yWorks, which also has a set of .Net libraries supporting pretty much every event to handle.
Using graphs makes it easy to interact with the metadata and hide most of the complexities, and it also allows you to easily use graph algorithms such as shortest path etc. Great for generating Dimensions and Point-In-Time tables!
The metadata itself can be easily stored in a relational database, I wouldn’t necessarily adopt a Graph Database such as Neo4j for this although this is an option of course. My view is that specifically the graph representation is key along with the event handling to interact with this representation.
The example below is generated in DGML from the free Virtual Enterprise Data Warehouse tool (see link here):
![]()
The engine created
Together these components create the ‘engine’ for data management, which can act on the inputs it receives (metadata settings) to adapt accordingly using generation technology. This frees up more time to focus on simplifying the design process itself. This is what I meant by stating we don’t need to worry about discussions covering Hash keys or Satellite splits. You can see this can all be automated.
Of course, this doesn’t meant we will stop looking into improvements in the concepts as there is always something to work on. But look at this as the work engineers perform on a car engine as opposed to mixing this up with driving the car. Data specialists such as myself would be doing the servicing, and to make sure updates are applied. As such we will always be interested in seeing what can be improved and how. But I argue we should have future discussions in this ”engine’ context instead of allowing discussions to appear to be zealous.
In short, the works never stops and we can always tune your engine to meet your demands. At the same time it is achievable to automate information management end-to-end and focus solely on the modelling.
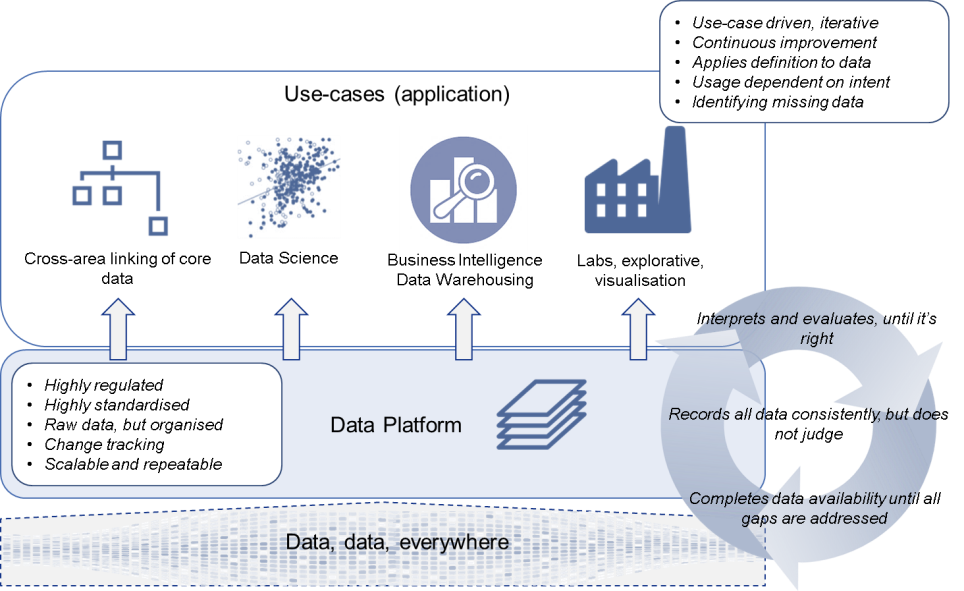
Next steps are to make sure we can connect information modelling and definitions (taxonomies, glossaries) to the graphs, so we can use these as the ‘steering wheel’ to guide the direction of our information and it’s management – illustrated by the image below. I want to be able to systematically / programmatically manage data integration through governance.
![]()
I have some time set aside to work on seeing how information modelling case-tools can be integrated into this thinking. Watch this space!